![[TBC]Java - 자료구조 (Data Structure)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbFO0Qg%2FbtrDEZP08x8%2FGYT4c7iEBImYJLRWFInLW1%2Fimg.png)
추가할 것: Hash Table / Deque /
데이터를 어떤 식으로 정리해서 활용할지를 다양한 방법을 통해 구현할 수 있도록 알고리즘으로 구체화한 것이다.
대부분의 자료구조는 특정 상황에 놓인 문제를 해결하는데에 특화 되어있다.
따라서 많은 자료구조를 알고 있으면, 어떤 상황이 닥쳤을때 해당 상황에 가장 적절한 자료구조를 사용해서 빠르고 정확하고 효율적이게 문제를 해결할 수 있다.

Stack
프링글스 통
> LIFO (Last In First Out) - 후입 선출
> 입력과 출력이 하나의 방향으로 진행되는 '제한적 접근'
> 데이터를 한번에 하나씩 넣고 뺀다. (한 번에 여러 개 불가)
어떨 때 쓰일까??
웹 브라우저에서 뒤로 가기 / 앞으로 가기 구현, 응용 프로그램에서 Ctrl + Z 등등..
작동 원리 구현
몇몇 메소드가 제외되어있지만, 직접 스택을 구현해 본다면 아래의 코드처럼 가능할 것이다.
import java.util.*;
public class stack_prac {
public static void main(String[] args) {
Stacking stacking = new Stacking();
for(int i = 0; i<11; i++){
stacking.push(i);
}
System.out.println(stacking.show());
for(int i = 0; i<11; i++){
System.out.print(stacking.pop() + " ");
}
}
}
//직접 스택 클래스를 만들고 스택의 기능을 구현
class Stacking {
private ArrayList<Integer> listStack = new ArrayList<Integer>();
public void push(Integer data) {
listStack.add(data);
}
public Integer pop() {
if (listStack.size() == 0) {
return null;
} else {
return listStack.remove(listStack.size() - 1);
}
}
public int size() {
return listStack.size();
}
public Integer peek() {
if (listStack.size() == 0) {
return null;
} else {
return listStack.get(listStack.size() - 1);
}
}
public String show() {
return listStack.toString();
}
public void clear() {
listStack.clear();
}
}
여기서 ArrayList를 사용했다는 점을 주목하면 좋을 것 같은데, ArrayList를 사용했기 때문에 결과적으로는 구조적인 문제가 있을 수 있는 클래스가 된다.
Stack은 항상 FILO / LIFO (마지막에 들어온 놈이 제일 처음으로 나감)의 성질을 항상 가지고 있어야 의미가 있는데 ArrayList가 가지고 있는 메서드 중에서는 이 LIFO의 성질을 지키지 않는 것들도 포함하고 있기 때문이다.
remove(), add(), get() 등..
이 결함을 해결하기 위해서 Deque를 쓸 수 있다.
Stack 메서드
자바에서는 기본적으로 Stack 과 Queue 클래스를 가지고 있으며 이 클래스를 활용해서 스택과 큐를 간편하게 구현할 수 있다.

Queue
First In First Out - 선입 선출
데이터를 한번에 하나씩만 넣고 뺄 수 있다.
입력과 출력 방향이 다르다.
입력 방향 ------[4, 3, 2, 1, 0]-------> 출력 방향 0, 1, 2, 3, 4 순으로 나온다
데이터가 입력된 순서대로 처리할 때 주로 사용한다. (BFS 탐색, 프린터 / 게임 매칭 큐, 영상 스트리밍 사이트 등)
큐는 특히 프린터 같은 컴퓨터 장치들 사이에서 데이터를 주고 받을때, 각 장치 간의 속도나 시간 차이를 극복하기 위해
임시 기억장치의 자료구조로써 Queue를 사용한다. 이것을 버퍼(Buffer)라고도 한다. (버퍼링할때 그 버퍼)
작동 원리 구현
import java.util.*;
public class Queue_prac {
public static void main(String[] args) {
Queue que = new Queue();
for (int i = 0; i < 11; i++) {
que.add(i);
}
System.out.println(que.show());
for (int i = 0; i < 11; i++) {
System.out.print(que.poll() + " ");
}
}
}
// [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
// 0 1 2 3 4 5 6 7 8 9 10 //선입선출 된 것을 확인할 수 있다.
class Queue {
ArrayList<Integer> listQueue = new ArrayList<>();
public void add(Integer data) {
listQueue.add(data); //큐에 data 값 삽입
}
public Integer poll() {
if (listQueue.size() == 0) {
return null;
} else {
return listQueue.remove(0); //큐 리스트의 0번째 인덱스 삭제후 반환
}
}
public int size() {
return listQueue.size();
}
public Integer peek() {
if (listQueue.size() == 0) {
return null;
} else {
return listQueue.get(0); //큐 리스트의 0번째 인덱스의 값 반환
}
}
public String show() {
return listQueue.toString();
} //큐 리스트를 String 타입으로 바꾸고 반환
public void clear() {
listQueue.clear();
} // 큐 리스트 전체 삭제
}
Queue와 Array
큐는 배열을 사용하여 굴릴 수도 있지만 여러 비 효율적인 단점들이 나타난다.
- 뒷부분 원소들의 쏠림현상 발생 >> poll로 뺄 때마다 모든 원소를 하나씩 앞으로 옮겨야 함 (비효율)
- 배열의 크기가 고정이기 때문에 들어와야 하는 데이터의 수가 유동적일때 대처가 번거롭다
이를 해결하기 위해 원형 큐를 사용할 수 있다.
자바 [JAVA] - 배열을 이용한 Queue (큐) 구현하기
자료구조 관련 목록 링크 펼치기 더보기 0. 자바 컬렉션 프레임워크 (Java Collections Framework) 1. 리스트 인터페이스 (List Interface) 2. 어레이리스트 (ArrayList) 3. 단일 연결리스트 (Singly Li..
st-lab.tistory.com
Queue 메서드

Tree
트리부터는 본격적으로 느낌이 달라진다.
스택이나 큐를 그리고 여지까지 모든 데이터를 다룰때는 일직선의 형태를 띤 선형 구조로만 배워왔는데 트리는 비 선형적 구조를 띈 자료, 즉 일직선으로 나타낼 수 없는 형태이다.
파일 탐색기, 토너먼트 대진표, 회사 조직도, 가계도 등이 대표적인 트리의 사용 예이다.

- 트리의 구조는 Root 라는 최상위의 데이터부터 시작된다.
- 여러 개의 데이터들을 간선 (edge)로 연결한다.
- 각각의 데이터를 노드(Node)라고 한다.
- 두 개의 노드가 상/하위로 연결되면 각각 부모 노드(Parent Node), 자식 노드(Child Node)라 한다.
- 자식이 없는 노드는 리프 노드(Leaf Node)라 한다.
깊이(Depth)
트리 구조에서, 루트로부터 특정 하위 노드까지의 깊이(depth)를 표현할 수 있다.
(위의 그림을 예로 들면 데이터 4의 깊이는 2이다)
레벨(Level)
트리 구조 에서 같은 깊이를 갖는 노드를 묶어 레벨로 표현 가능하다.
위 그림에서 depth가 0인 (1) 노드는 level 1이고 (2), (3) 노드는 level 2..... (8), (9), (10) 노드는 level 4이다.
높이(Height)
리프 노드를 기준으로 루트까지의 높이를 표현할 수 있다. 리프 노드의 높이를 0으로 한다.
서브 트리(Sub Tree)
트리의 내부에 또 다른 트리구조를 갖는 작은 트리를 말한다. 위 그림의 (2 4 5 8 9) / (2 4 5) / (3 6 7 10) 등을
서브 트리라고 할 수 있다.
Binary Tree
Binary Tree(이진트리)는 트리의 한 종류로써, 하위 노드가 최대 2개인 노드들로 구성된 트리이다. 이 2개의 하위 노드는 다시 왼쪽 자식과 오른쪽 자식 노드로 구분이 가능하다.
이진트리는 자료의 삽입과 삭제 방법에 따라서 아래의 그림처럼 3가지 형식으로 나눌 수 있다

| Complete Binary Tree (완전 이진 트리) | * 마지막 레벨을 제외 한 모든 노드가 가득 차 있어야 함. * 마지막 레벨의 노드는 가득 차있지 않아도 되지만 왼쪽이 항상 채워져 있어야 한다. |
| Full Binary Tree (정 이진 트리) | * 각 노드가 0개 or 2개의 자식 노드를 갖는다. |
| Perfect Binary Tree (포화 이진 트리) | * Full 이면서 Complete인 Binary Tree * 모든 리프 노드의 레벨이 같고, 모든 레벨의 노드가 가득 차있다. |
Binary Search Tree
Binary Search Tree (BST - 이진 탐색 트리)는 Binary Tree의 형태에서 다음의 조건이 추가된 트리를 말한다.
모든 왼쪽 자식의 값이 루트나 부모보다 작다.
모든 오른쪽 자식의 값이 루트나 부모보다 크다.
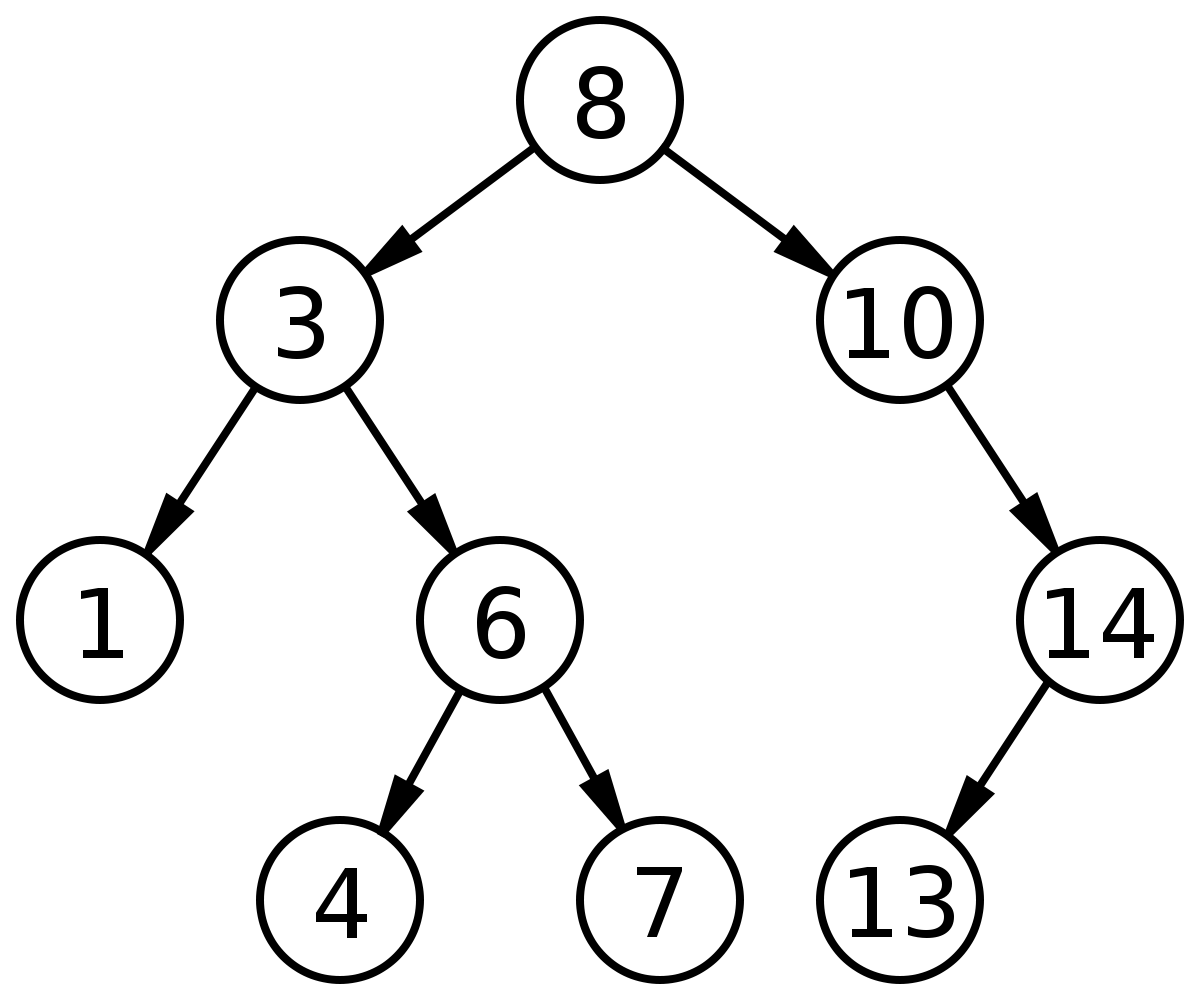
Binary Search Tree와 Binary Search Algorithm 은 다른 개념이라는 사실을 알아둘 것.
트리는 자료구조이고, 알고리즘은 문제를 해결하는 '방법'이다.
트리 순회 방식
Tree Traversal
특정 목적을 위해서 트리의 모든 노드를 하나씩 탐색하는 것을 트리 순회(Tree Traversal)이라고 한다. 트리는 비 선형적 구조이기 때문에 배열처럼 접근하는 방식이 아니라 다음의 3가지의 방법을 통해 순회한다.
| 전위 순회 | Pre-order Traverse | Root → Left → Right |
| 중위 순회 | Inorder Traverse | Left → Root → Right |
| 후위 순회 | Post-order Traverse | Left → Right → Root |

//전위 순회
public ArrayList<Integer> preorderTree(Node root, int depth, ArrayList<Integer> list) {
if (root != null) {
list.add(root.getData());
preorderTree(root.getLeft(), depth + 1, list);
preorderTree(root.getRight(), depth + 1, list);
}
return list;
}
//중위 순회
public ArrayList<Integer> inorderTree(Node root, int depth, ArrayList<Integer> list) {
if (root != null) {
inorderTree(root.getLeft(), depth + 1, list);
list.add(root.getData());
inorderTree(root.getRight(), depth + 1, list);
}
return list;
}
//후위 순회
public ArrayList<Integer> postorderTree(Node root, int depth, ArrayList<Integer> list)
if (root != null) {
postorderTree(root.getLeft(), depth + 1, list);
postorderTree(root.getRight(), depth + 1, list);
list.add(root.getData());
}
return list;
}Graph
그래프는 정점(Vertex)라고 불리는 여러 데이터들이 서로 연결되어 있는 관계를 표현한 자료구조이다.
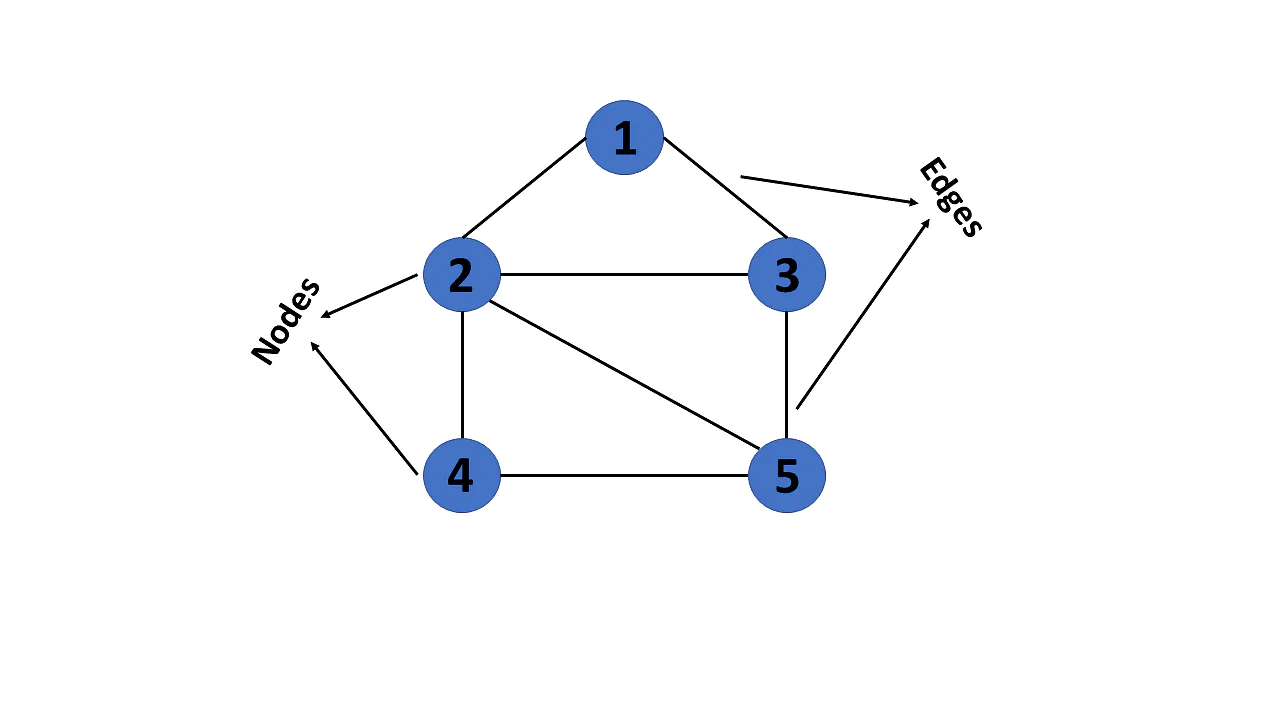
하나의 점을 정점(vertex)라고 하고 이런 정점들(vertices)을 연결하는 간선(edge)으로 구성되어있다. 정점이 간선으로 직접 연결되어 있으면 직접적인 관계, 몇 개의 정점과 선을 걸쳐 간접적으로 연결되어 있으면 간접적인 관계가 된다.
그래프를 표현할 수 있는 방법으로 인접 행렬 (Adjacency Matrix)과 인접 리스트 (Adjacency List)가 있다.
인접 행렬
Adjacency Matrix
인접 행렬은 서로 다른 vertices들이 인접해 있는 상태인지 2차원 배열의 형태로 나타낼 수 있다.
만약 A라는 정점과 B라는 정점이 연결되어 있다면 1(true)을, 이어져 있지 않다면 0(false)으로 표시한다.

위의 그림은 방향성이 없는 무향(무방향) 그래프 (undirected graph)로 A -> B로 갈 수 있고 B ->A 또한 가능하다. 방향성이 있는 그래프(directed graph)는 말 그대로 A --> B 형식으로 연결되어 있을 때, A -> B로는 갈 수 있지만 B -> A로는 못 간다.
위의 예는 정점끼리 연결되어 있는지만 알 수 있지만 정점끼리의 관계에 대해서는 자세히 알 수 없다.
이를 비 가중치 그래프라 한다.
정점끼리의 관계에 대한 가중치(정점끼리의 연결 강도)를 표현한 가중치 그래프도 있는데, 아래의 사진처럼 정점끼리 서로 얼마나 강도 높게 연결되어 있는지 알 수 있다. 이를 이용하면 내비게이션에서 경로별 거리등을 나타낼 수 있다.

인접 리스트
Adjacency List
인접 리스트는 위의 인접 배열과는 다른 방식인 리스트의 형태로 각 정점이 어떤 정점과 인접하는지 표현한다.
각 vertex마다 하나의 리스트를 갖고 있고, 이 리스트는 자신과 인접한 다른 정점을 담고 있다.

위 그림에서 리스트 안의 순서는 보통 중요하지 않지만, 정점의 우선순위가 있다면 고려해서 구현해야 할 것이다. 그렇지만 보통 우선순위를 다뤄야 할 때는 heap이나 queue같이 더 적절한 자료구조를 사용하는 게 더 합리적이다.
- 인접 리스트는 연결된 정점들만 표시하므로 메모리를 효율적으로 관리하고 싶을 때 사용한다.
- 인접 리스트에 비해 인접 행렬은 연결 가능한 모든 경우의 수를 저장하기 때문에 상대적으로
메모리 공간을 많이 차지한다. (vertex의 개수만큼 loop를 돌아야 함)
Graphs in Data Structure: Overview, Types and More [Updated] | Simplilearn
Explore what are graphs in data structure, its types, terminologies, representation and operations. Read on to know how to implement code in graph data structure. Keep learning!
www.simplilearn.com
'programming > JAVA' 카테고리의 다른 글
| Java - SOLID (0) | 2022.06.13 |
|---|---|
| Java - 재귀 (0) | 2022.05.25 |
| Java - Effective cont. (0) | 2022.05.20 |
| Java - Effective (0) | 2022.05.19 |
| Java - Inner Class (0) | 2022.05.18 |