
파일 입출력 (I/O)
바이트 기반 스트림
입출력 단위가 1byte인 바이트 기반 스트림으로 InputStream, OutputStream가 있다.
스트림은 한 번만 그리고 단 방향으로만 데이터를 전송하기 때문에 입출력을 동시에 하려면 스트림을 각각 만들어야 한다. 바이트 기반 입출력 스트림은 대상에 따라 종류가 달라진다.
| 입력 스트림 | 출력 스트림 | 입출력 대상 |
| FileInputStream | FileOutputStream | 파일 |
| PipedInputStream | PipedOutputStream | 프로세스 (프로세스 간의 통신) |
| ByteArrayInputStream | ByteArrayOutputStream | 메모리(byte계열) |
| AudioInputStream | AudioOutputStream | 오디오장치 |
입출력을 스트림을 사용하기 위해서는 java.io 패키지 안에 있는 해당 입출력 클래스를 import 해야 한다.
입출력 스트림의 메서드를 이용해서 간단하게 사용 가능함.
| 입력 스트림 | 출력 스트림 |
| abstract int read( ) | abstract void write (int b) |
| int read (byte[ ] b) | void write (byte[ ] b) |
| int read (byte[ ] b, int off, int len) | void write (byte[ ] b, int off, int len) |
입출력 스트림을 보조하기 위한 보조 스트림도 있는데 , 그 자체로 입출력을 한다기보다는 입출력 스트림의 기능을 향상하거나 새로운 기능을 추가할 수 있다.
BufferedInputStream이라는 보조 스트림은 버퍼라는 바이트 배열을 가지고 있고 이 버퍼를 통해 메인 입출력 스트림이 한꺼번에 많은 데이터를 입출력할 수 있도록 보조 공간을 제공한다라고 볼 수 있겠다.
입출력 스트림을 먼저 만들고 ---> 이를 이용해서 보조 스트림 생성
//먼저 메인 입출력 스트림 생성
FileInputStream file = new FileInputStream("Test.txt");
// 메인 입출력 스트림을 통해 보조 스트림 생성
BufferedInputStream bfile = new BufferedInputStream(file);
bfile.read(); //보조스트림 BufferedInputStream으로부터 데이터를 읽는다.
더 다양한 보조 스트림들이 존재한다. (추가 예정)
문자 기반 스트림
자바에서 한 문자를 의미하는 char 타입은 2byte를 가지고 있어 바이트 기반 입출력 스트림으로는 2byte인 문자를 처리하는데 어려움이 있다. 이를 보완하기 위해서 문자 기반 스트림 FileReader와 FileWriter 가 있다.
| 바이트 기반 스트림 | 문자 기반 스트림 | |
| InputStream | ---------------------> | Reader |
| OutputStream | ---------------------> | Writer |
예를 들어 바이트 기반 스트림 FileInputStream을 문자 기반 스트림으로 바꾸면 FileReader가 된다. FileOutputStream은 FileWriter 가 된다.
바이트 기반 스트림을 통해 한글을 읽으면 글자가 깨져서 나온다. 한글은 한 글자가 2바이트 이기 때문이다.
공식문서 링크
Reader (Java Platform SE 7 )
reset public void reset() throws IOException Resets the stream. If the stream has been marked, then attempt to reposition it at the mark. If the stream has not been marked, then attempt to reset it in some way appropriate to the particular stream, for ex
docs.oracle.com
Writer (Java SE 11 & JDK 11 )
Returns a new Writer which discards all characters. The returned stream is initially open. The stream is closed by calling the close() method. Subsequent calls to close() have no effect. While the stream is open, the append(char), append(CharSequence), app
docs.oracle.com
File
자바에서는 File 클래스를 통해 파일과 디렉터리에 접근이 가능하다.
파일 인스턴스를 생성한다고 해서 파일이 생성되는 것이 아니고, 생성자 자리에 파일의 이름을 설정해주고,
createNewFile( ) 메서드를 통해 호출해야 비로소 파일이 만들어진다.
File file = new File("study/IOtesting.txt"); //File 객체 생성 (매개변수 = 파일 이름)
file.createNewFile(); //createNewFile( )메서드로 실제 파일 생성
System.out.println(file.getPath()); //파일의 경로 String으로 반환
System.out.println(file.getParent()); //파일의 상위 디렉토리를 String or 파일로 반환
System.out.println(file.getCanonicalPath()); //파일의 정규 경로를 String으로 반환
System.out.println(file.canWrite()); //쓸수 있는 타입인지 boolean으로 반환
}
}
study\IOtesting.txt
study
C:\Users\*****\Desktop\****\intelliJ_Projects\study\IOtesting.txt
true
File (Java Platform SE 7 )
Returns the absolute pathname string of this abstract pathname. If this abstract pathname is already absolute, then the pathname string is simply returned as if by the getPath() method. If this abstract pathname is the empty abstract pathname then the path
docs.oracle.com
스레드 (Thread)
스레드는 간단히 말해서 프로세스의 자원을 이용해 실제로 작업을 진행하는 것을 말한다.
여기에서 프로세스는, '현재 실행 중인 프로그램'을 의미하며, 프로그램을 실행하게 되면 OS에서 필요한 자원(메모리)을 할당받아 프로세스가 된다.
프로세스는 해당 프로그램을 수행하는데 필요한 데이터와 자원 그리고 스레드로 구성되어 있다. 따라서 프로세스에는 최소 1개 이상의 스레드가 존재해야 하는데 이때 2개 이상의 스레드가 존재하는 프로세스를 멀티-스레드 프로세스라고 한다.
스레드를 프로세스라는 공장에서 일하는 일꾼으로 생각하면 편할 것 같다.
멀티 스레드
멀티 태스킹 = 두 가지 이상의 작업을 동시에 처리하는 것
멀티 프로세스= 애플리케이션 단위에서의 멀티 태스킹
멀티 스레드 =애플리케이션 내부에서의 멀티 태스킹
멀티 스레딩의 장점
- CPU의 사용률을 향상한다
- 자원을 효율적으로 사용할 수 있다.
- 유저에 대한 응답성이 향상된다.
- 작업을 분리할 수 있어 코드가 간결해진다.
위와 같은 장점도 있지만 멀티 스레드 프로세스는 여러 스레드가 같은 프로세스 안에서 자원을 공유하면서 작업을 진행하기 때문에 동기화나 교착상태(deadlock) 같은 발생할 수 있는 문제들을 개발할 때 잘 고려해야 한다.
메인 스레드
모든 자바 프로그램은 메인 스레드가 main( ) 메서드를 실행하면서 시작한다. 즉 여태까지 항상 스레드를 사용하고 있었던 것이다. 메인 스레드는 main( ) 메서드의 첫 코드부터 위에서 아래로 진행하며 실행하고, main( ) 메서드의 마지막 코드를 실행하거나 return 문을 만날 때 실행을 종료한다.
싱글 스레드 프로그램은 메인 메서드가 종료되면 프로세스도 끝나지만, 멀티 스레드 프로그램은 하나라도 실행 중인 스레드가 있다면 프로세스가 종료되지 않고 기다린다. 메인 메서드가 끝나더라도 마찬가지다.
스레드의 구현과 실행
멀티 스레드로 실행하는 프로그램을 만들려면 먼저 몇 개의 작업을 동시에 처리할지 정하고 각 작업별로 스레드를 만들어야 한다. main 스레드는 항상 존재하기 때문에 메인 이외의 병렬 작업의 수만큼 스레드를 만든다. 자바에서는 스레드가 객체로 생성되기 때문에 사용하기 위해 클래스가 필요하다.
java.lang.Thread 클래스를 직접 인스턴스화 or Thread 클래스를 상속한 하위 클래스를 만들어 사용할 수도 있다.
스레드를 구현하는 방법은 1. Thread 클래스를 상속받거나, 2. Runnable 인터페이스를 구현하는 방법 두 가지가 있다.
어느 쪽을 하던 별 차이는 없지만 Thread클래스를 상속받으면 다른 클래스를 상속받을 수 없게 될 것이다. 따라서 보통 Runnable 인터페이스를 구현하는 방법이 일반적이다.
Thread 클래스로부터 직접 생성 (Runnable 구현)
java.lang.Thread 클래스로부터 스레드 객체를 생성하기 위해서는 Runnable 인터페이스 타입을 매개 변수로 갖는 생성자를 호출해야 한다.
// Thread 객체를 생성한다. (매개변수 - Runnable 인터페이스)
Thread thread = new Thread(Runnable target);Runnable은 스레드가 실행할 코드를 가진 객체라는 의미를 갖고 있다. 인터페이스 이기 때문에 구현을 해야 한다.
Runnable에는 run( )이라는 추상 메서드가 있는데, 이를 구현한 클래스에서 오버 라이딩해서 어떤 작업을 스레드가 처리할 것인지 명시를 한다.
//Runnable 인터페이스를 구현한다.
class threadTask implements Runnable{
public void run(){
...쓰레드가 실행할 코드...
}
}인터페이스 Runnable을 구현한 threadTask 클래스를 만들었다.
이 클래스의 객체를 생성하고 이것을 매개변수 값으로 해서 Thread 생성자를 호출하면 작업 스레드의 구현 완성
Runnable task = new threadTask();
Thread thread = new Thread(task); //Runnable 타입의 task 대입
--------------------------------------------------------------
// Runnable 익명 개체를 매개변수로 사용할 시
Thread thread = new Thread(new Runnable() {
public void run() {
쓰레드가 실행할 코드;
}
} );
--------------------------------------------------------------
// 람다식을 매개변수로 사용할 시
Thread thread = new Thread( () -> { 쓰레드가 실행할 코드} );
마지막으로 start( ) 메서드를 사용해야 작업 스레드를 실행할 수 있다. 생성만 한다고 실행되는 것은 아니다.
thread.start(); //작업 쓰레드가 매개변수로 받은 run()메서드를 실행Thread 하위 클래스로부터 생성
스레드가 할 작업 내용을 Thread의 하위 클래스로 스레드를 정의하면서 작업 내용을 포함시킬 수 있다.
큰 그림으로 보면 [ Thread클래스 상속 -> run( ) 메서드 오버 라이딩 -> start( ) 메서드로 실행 ]이다.
class WorkerThread extends Thread {
@Override
public void run(){
..쓰레드야 이걸 해줘 코드..
}
}
Thread thread = new WorkerThread();
thread.start();
--------------------------------------------------------------
//익명 객체로 사용
Thread thread = new Thread(){
public void run() {
쓰레드 이걸 실행해줘 코드;
}
}
thread.start();스레드의 이름
스레드도 이름을 지정할 수 있다. 지정을 하지 않으면 'Thread-1' 같은 형식으로 이름이 정해진다.
setName( )과 getName( ) 메서드가 Thread 클래스의 인스턴스 메서드로써 포함되어 있기 때문에 스레드 객체의 참조를 통해 설정할 수 있다.
thread.setName("쓰레드 명");
thread.getName(); //쓰레드 명Thread클래스를 상속받은 경우, set, getName( ) 메서드를 바로 호출할 수 있지만, Runnable을 구현했을 경우 Thread 클래스의 정적 메서드인 currentThread( )를 호출해서 스레드에 대한 참조를 얻어야 호출이 가능하다.
Thread thread = Thread.currentThread();Thread 동기화 & 상태
동기화 메서드 & 블록
싱글 스레드 프로그램
- 한 개의 스레드가 객체를 점유해서 사용함.
멀티 스레드 프로그램
- 여러 개의 스레드가 객체를 공유
- 스레드가 사용 중인 다른 객체를 다른 스레드가 변경 못하게 하려면 객체를 잠거야 함
- (WHY) 각각의 스레드가 한 변수의 값을 바꾸는 기능이 있을 때, 동시에 객체의 변수에 접근해서 값을 변경한다면 변수의 값이 의도와 다르게 변할 수 있다. 이걸 막아야 함.
- 멀티 스레드 프로그램에서 단 하나의 스레드만 실행 가능한 코드 영역 == 임계 영역 (Critical Section)
- 이 임계 영역을 지정하기 위해 동기화 메서드와 동기화 블록 제공 -> 메서드 선언에 synchronized 키워드
- 메서드 전체를 동기화할 수도 있고, 일부분만 동기화할 수 있다.
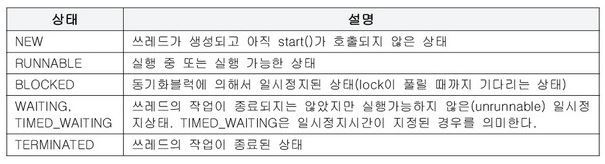
스레드의 상태
- 스레드 객체를 생성하고 start( ) 메서드를 호출하면 바로 실행되는 것이 아니라 실행 대기 상태로 진입한다.
- 실행 대기 상태 (Runnable state)
아직 스케쥴링이 되지 않아 실행을 기다리는 상태 - 실행 상태 (Running state) :
실행 대기 상태에 있는 스레드 중에서 스레드 스케쥴링으로 선택된 스레드가 CPU를 점유하고 run( ) 메서드 실행 - 실행 상태 스레드는 run( )을 모두 실행하기 전에 스레드 스케쥴링에 의해 다시 실행 대기상태가 될 수 있다.
<위아래 반복할 수 있음> - 그리고 다른 실행 대기 상태에 있는 스레드가 선택되어 실행상태가 된다.
- 이렇게 스레드는 실행 대기 상태 - 실행 상태를 반복적으로 왔다 갔다 하며 자신의 run( ) 메서드를 조금씩 실행.
- 종료 상태 (Dead state) :
실행 상태에서 run ( ) 메서드가 종료되면 더 이상 실행 코드가 없는 것이기 때문에 스레드 실행 멈춤
- 일시 정지 상태 (Blocked state) :
간혹 경우에 따라 실행 상태에서 실행 대기 상태로 가지 않음. 스레드를 실행할 수 없는 상태 - 이때는 일시 정지 상태에서 -> 실행 대기 상태로 가야 다시 실행 상태로 갈 수 있다.
- 스레드 상태 확인 : getState( ) 메서드
- getState( ) 메서드는 Thread.State의 enum 상수
(NEW, RUNNABLE, WAITING, TIMED_WAITING, BLOCKED, TERMINATED)로 구성
- getState( ) 메서드는 Thread.State의 enum 상수
스레드의 상태 제어
정교한 멀티 스레드 프로그램을 짜기 위해서는 구체적인 스레드 상태 제어가 필요하다.
이때 스레드의 상태 변화를 위해 스레드 스케쥴링과 관련된 메서드를 사용해서 제어를 한다.


스케쥴링 관련 메서드
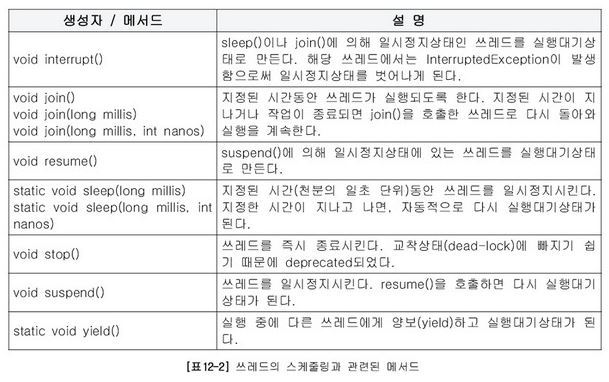
yield( ) - 다른 스레드에게 실행을 양보
스레드는 반복적인 실행을 포함하는 경우가 많은데 가끔 이런 반복이 무의미한 반복이 될 수 있다.
이때 무의미한 반복 실행을 다른 스레드에게 양보하고 해당 스레드는 실행 대기 상태로 가는 게 전체 프로그램의 성능에 도움이 될 수 있다.
join( ) - 다른 스레드의 종료를 기다린다
스레드는 다른 스레드들과 독립적으로 실행되는 것이 기본이지만 다른 스레드가 종료될 때까지 기다려야 할 경우도 있을 수 있다. 예를 들어 계산을 완료한 결괏값이 필요한 스레드가 있을 때 실제 계산을 하는 스레드가 완료될 때까지 기다리는 것이 있겠다.
wait( ), notify( ), notifyAll( ) - 스레드 간의 협업
경우에 따라 두 개의 스레드를 번갈아가며 실행해야 할 경우가 있다. 정확하게 의도적으로 교대작업이 필요할 때 자신의 작업이 끝날 경우 자신은 일시 정지 상태로 전환하고 상대방 스레드를 일시 정지상태에서 풀어줄 수 있다.
공유 객체라는 개념이 있는데 공유 객체는 두 스레드가 작업할 내용을 각각 동기화 메서드 synchronized로 구분한다.
한 스레드가 작업을 완료 -> notify( ) 메서드 호출 -> 일시 정지 상태의 다른 스레드를 실행 대기상태로 전환 ->
자신을 wait( ) 메서드를 이용해 일시 정지 상태로 만든다. wait(long timeout)이나 wait(long timeout, int nanos)를 이용하면 notify( ) 메서드 없이 지정된 시간이 지나면 자동으로 실행 대기 상태가 된다.
notifyAll( ) 메서드는 notify( )와 동일한 역할을 하지만 notify( ) 메서드는 한 개의 일시 정지된 스레드를 실행 대기상태로 바꾸고 notifyAll( ) 메서드는 wait( ) 메서드에 의해 일시 정지된 모든 스레드를 실행 대기상태로 전환한다.
wait, notify, notifyAll 메서드들은 synchronized 메서드나 블록 안에서만 사용 가능.
Thread클래스가 아닌 Object클래스에 선언된 메서드라 모든 공유 객체에서 호출 가능.
Thread Pool
스레드의 무분별한 증가나 스레드의 제어 문제로 인한 성능 저하를 방지하기 위해 스레드 풀이라는 것을 사용해야 한다. 스레드 풀은 작업에 사용되는 스레드의 수를 미리 설정한 수 대로 생성한다.
여기에서 풀이라는 단어는 미리 초기화가 되어 바로 사용할 수 있는 상태의 객체 집합을 의미한다.

스레드 풀 생성
스레드 풀의 구현 객체는 Executor 클래스 메서드로 생성할 수 있다.
| 리턴타입 | 메서드 | 특징 |
| void | shutdown( ) | 작업 큐에 남아있는 모든 작업을 처리한 뒤 종료 |
| List | shutdownNow( ) | 작업 큐에 남아있는 작업과 상관없이 종료하고, 처리하지 못한 작업(Runnable)의 목록을 List로 반환 |
| boolean | awaitTermination(long timeout, TimeUnit unit) | shutdown( ) 메서드를 호출하고, 모든 작업 처리를 timeout 시간 안에 완료하면 true, 완료하지 못하면 작업 스레드 들을 interrupt( ) {실행 대기상태 전환}하고 false 반환 |
JVM (간단 정리)
운영체제에 독립적인 개발을 할 수 있다.
OS에 맞는 JVM 버전이 따로 존재 (Windows, Linux, Mac..)
극한의 효율을 추구한다 (왜 컴파일 -> 런타임 할까?) //런타임 시작( main()부터)
잘 정리된 메모리 공간을 왔다 갔다 하면서 필요 자원을 그때그때 끄집어옴
JVM = 식당
주문받고 재료 사 오고 그때 손질하고 하면 너무 느림
(컴파일 때 미리 재료 손질을 다 해놓고 정리해 놈) -> 런타임 때 준비된 것 해서 요리하기
JVM 구조
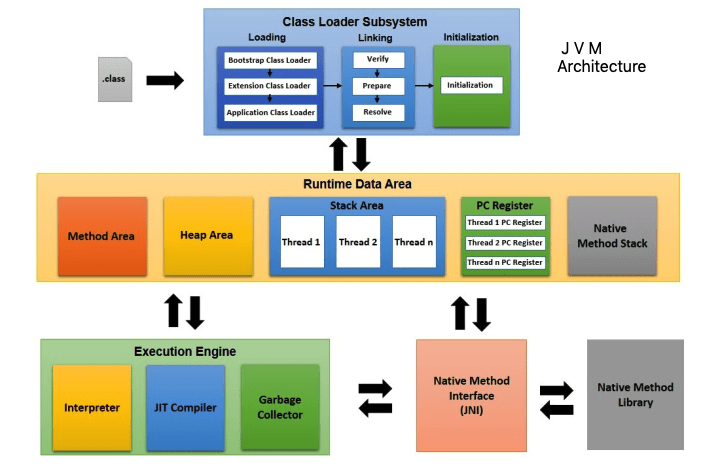
컴파일된. class 파일을 실행할 수 있도록 Class Loader가 확인하고 정리하는 역할을 먼저 수행한다. 그리고 method area, stack, heap 영역 등에 정리된 데이터를 규칙에 맞게 보관한다.
Method Area(서랍)
a.k.a [Code Area], [Static Area], [Class Area]
클래스에 필요한 모든 정보를 보관한다.
(객체 생성을 아직 안 했다면, 모든 정보를 여기에 일단 싹 다 때려 넣는다)
클래스 이름, 제어자, 클래스 구조, 생성자, 필드, 스태틱 변수(클래스 변수), 상수, 메서드 등
class 변수 / class 메서드는 힙&스택 영역이 아닌, Method Area에 저장되고 GC관리 영역 밖에 존재한다.
따라서 static의 특징인 '모든 객체가 공유하는 메모리'가 성립하는 것이다.
Constant pool (상수 풀)
상수 풀은 Heap영역의 Permanent Area(고정 영역)에 생성되고 자바 프로세스의 종료까지 계속 유지되는 메모리 영역이다. 상수 풀 영역은 클래스나 인터페이스별로 할당되기 때문에 개체의 인스턴스와 연결된 상태가 아니다.
String부분 정리::
String a = "abc"
String b = "abc"
Constant Pool에 "abc" 리터럴로써 생성된다. 여기에서 = 를 통해 pool 영역의 리터럴 주소를 참조하게 된다.
따라서 a == b 가 성립하는데 pool 안의 리터럴의 주소가 동일하기 때문
String a = new String("abc");
힙 영역에 배열 객체로써 생성된다. 여기에서 =를 통해 a가 Heap영역의 객체 주소를 참조한다.
왜 나눔? = 리터럴 재사용 + 메모리 절약
[Java-26] 자바 new & Heap, Constant pool
Java New Keyword 🐵 new 키워드 이해하기 (new Operator) 자 저번에는 우리가 어떻게 Class를 생성하고 만드는지, 그리고 클래스의 간단한 종류에 대해서 알아 보았다. 그럼 다시 간단한 클래스를 정의 해
catch-me-java.tistory.com
Stack과 Heap
Stack
일종의 자료구조 - 데이터를 저장하는 방식 중 하나 (LIFO - Last In First Out)
참조 변수/ 매개변수/ 지역변수/ 리턴 값 및 연산 시 일어나는 값들의 임시 저장 (메서드 종료 시까지)
메서드 호출 시 해당 메서드를 위한 공간인 Method Frame이 생성된다.
Method Frame들이 stack에 호출되는 순서대로 쌓이고, Method의 동작이 끝나면 역순으로 제거됨.
Heap
JVM에는 단 하나의 힙 영역 존재하고 JVM실행 시 자동 생성된다.
new로 만들어진 모든 객체, 인스턴스 변수, 배 열등을 저장
Person person = new Person();
new Person() (객체의 생성) -> 실행되면 Heap영역에 인스턴스 생성 -> 그 주소를 Stack에 있는 person 변수에게 넘김.
즉 객체를 다룬다 == Stack영역의 참조 변수를 통해 Heap영역에 존재하는 객체를 다룬다.
Heap 영역 = 실제 객체의 값이 저장되는 공간
Pc Register, Native Method Area
자바 프로그램 실행될 때 필요한 도구들
- JVM명령어
-다른 언어 기능 호출
Garbage Collection(GC)
쓸모 없어진 객체를 청소해주는 기능 (Heap 영역의 객체만 정리)

Young Gen: (가비지 컬렉터: Minor GC)
- 새롭게 생성된 객체가 할당되는 곳 (많은 객체의 생성과 삭제가 반복된다)
Old Gen: (가비지 컬렉터: Major GC)
- Young Gen 영역에서 살아남은 객체들이 여기에 복사되고, 보통 Young 영역보다 크게 할당되고 크기가 커서 가비지가 적게 발생한다.
Young과 Old영역은 서로 다른 메모리 구조로 되어있어 세부적인 동작 방식은 다르지만 기본적으로 GC가 실행될 경우
2단계로 진행된다.
1. Stop The World
GC 실행을 위해 잠시 프로그램의 실행을 멈춘다. GC를 실행하는 스레드를 제외한 모든 스레드의 작업이 중단된다. GC작업이 끝나면 다시 재개된다.
프로그램이 정지하는 것과 마찬가지 -> 자주 쓰면 성능 하락?

2. Mark And Sweep
Mark - 사용하는 메모리와 사용하지 않는 메모리를 식별하는 작업)
Sweep - Mark단계에서 사용하지 않는 메모리로 식별된 메모리를 해제하는 작업
'programming > JAVA' 카테고리의 다른 글
| [TBC]Java - 자료구조 (Data Structure) (0) | 2022.05.26 |
|---|---|
| Java - 재귀 (0) | 2022.05.25 |
| Java - Effective (0) | 2022.05.19 |
| Java - Inner Class (0) | 2022.05.18 |
| [TBC]Java - 컬렉션 프레임워크 (Collections Framework) (0) | 2022.05.17 |